
Nanopublication Network
What once took over 3 hours now happens in just seconds, making it possible for scientists around the world to share knowledge quickly and build a truly global network.
The challenge
Knowledge Pixels is spearheading the creation of the Nanopublication Network – a decentralized system for publishing, sharing, and querying verified scientific knowledge. Built on RDF and Semantic Web technologies, the Network serves researchers, publishers, and cultural institutions around the world.
The vision is ambitious: to scale this infrastructure into a global, collaborative knowledge graph. At its core, the Network relies on two key distributed services: the Nanopub Registry, which stores Nanopublications, and the Nanopub Query, which makes them searchable. These services constantly communicate with one another to keep the Network in sync whenever new Nanopublications are published.
But here’s the challenge: this communication quickly became a major bottleneck. Standard RDF formats are slow and inefficient, and each Nanopublication had to be fetched individually, causing repeated HTTPS requests and significant delays. To unlock the Network’s full potential, a faster, more efficient communication method was essential.
Summary of the issue:
-
Knowledge Pixels needed to scale the global Nanopublication Network (scientific knowledge graph).
-
The problem: slow communication between services (Registry & Query) due to inefficient RDF serialization formats.
-
This bottleneck made it impossible to scale.
Issues with the old system
Need to expand to a global scale
Slow service interactions
Inefficient RDF serializations
The solution
To solve the challenges Knowledge Pixels was facing, we turned to our open-source Jelly-RDF serialization format. Built on Google’s Protocol Buffers, Jelly is a fast, robust binary framework designed for efficiency. With its smart streaming compression, for this use case, Jelly delivers 2.5x faster serialization and 5x faster deserialization than any other RDF format. It also supports continuous streams of multiple RDF graphs or datasets – ideal for this use case.
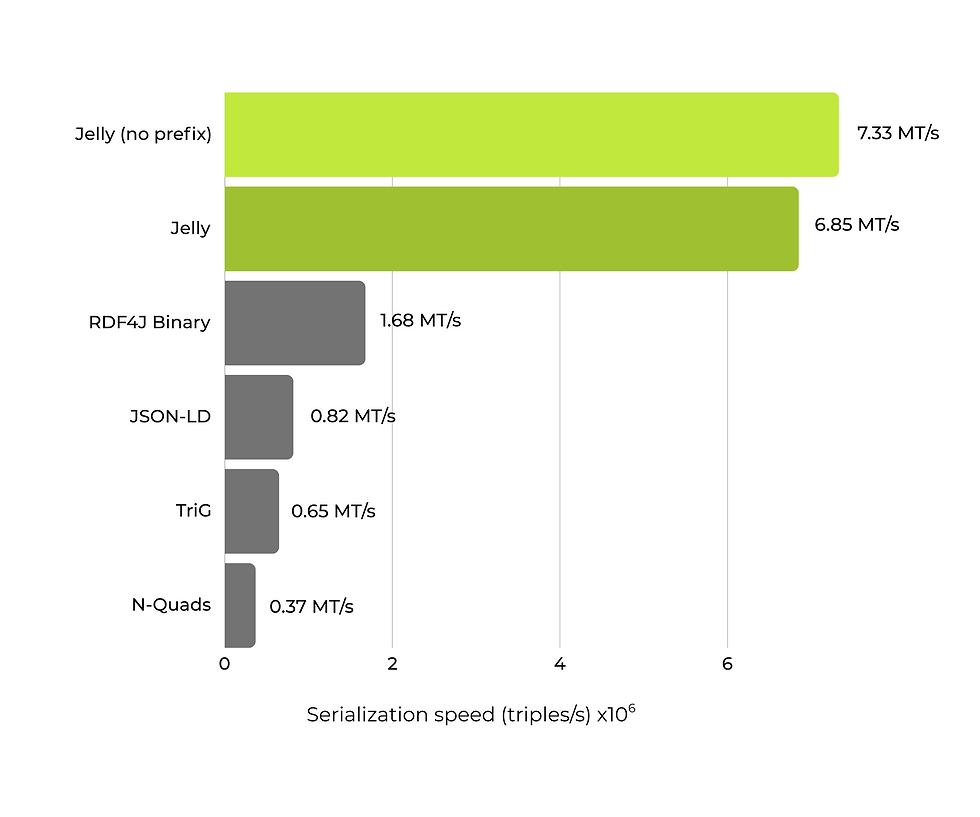
To back up our claims, we have conducted new benchmarks on the serialization and deserialization speed of different RDF formats on a dataset consisting from 10 million real nanopublications. Here, Jelly serialization reaches the speed of 7.33 million triples per second, with the deserialization being as fast as 15.23 million triples per second.
Jelly compared to other RDF formats
.png)
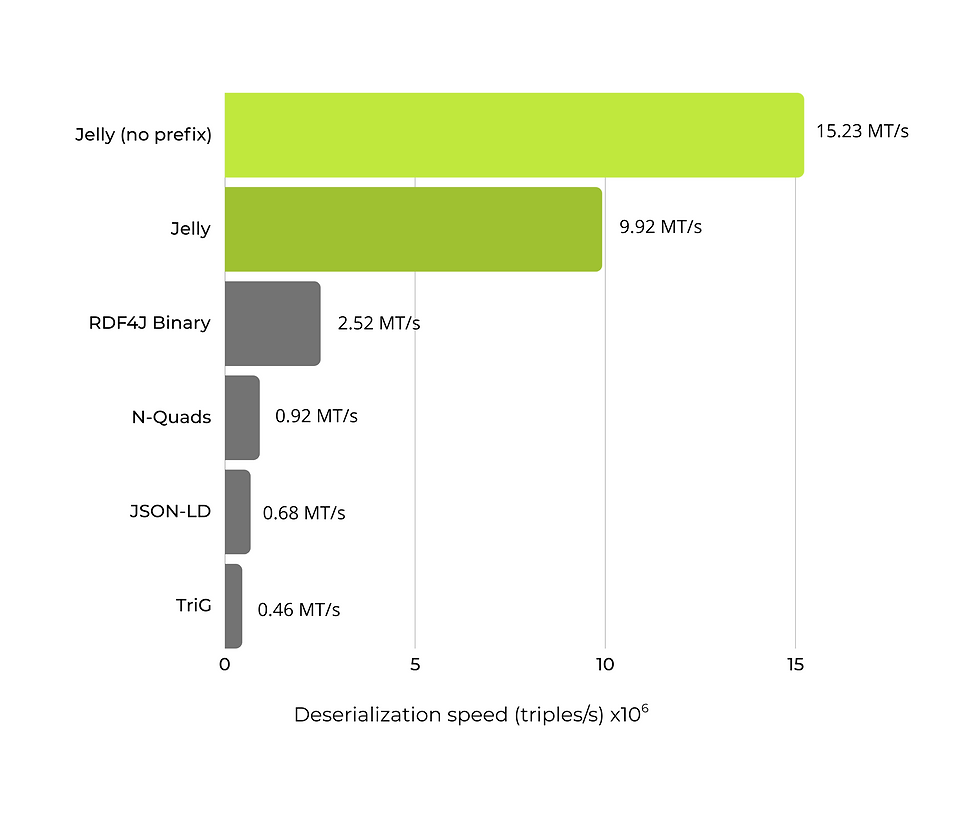
Platform: Oracle GraalVM 24+36.1, RDF4J 5.1.4, Jelly-JVM 2.10.3, Ryzen 9 7900 5.0 GHz, 64 GB RAM
Dataset: 10M nanopublications (RiverBench: nanopubs)
We integrated Jelly directly into the Nanopub Registry and Query services, replacing the slower TriG-based implementation. With Jelly, entire batches of Nanopublications can now be delivered as one streamlined data flow – used both for replication across Registries and for updating user-facing SPARQL endpoints.
The results speak for themselves: Jelly made Nanopublication data exchange dramatically more efficient – more than 19x faster to write, 16x faster to read, and 6x smaller than N-Quads. This leap in performance transforms the Nanopublication Network into a fast, scalable system and opens the door to a truly global, structured ecosystem for scientific knowledge.
Why Jelly?
19x
faster to write than N-Quads
16x
faster to read than N-Quads
6x
6x smaller than N-Quads
The result
The keys to success were Jelly’s outstanding performance, proven stability, and its seamless integration with RDF4J, which made implementation fast and straightforward. In full-scale deployment, the results spoke for themselves: retrieving over 60,000 Nanopublications (1.4 million quads) now takes under 4 seconds – down from more than 3 hours.
This breakthrough made communication between services virtually effortless, consuming less than 1% of total system time. With the bottleneck removed, the Nanopublication Network can now scale to the size required for a truly global scientific knowledge graph.
We documented this case together with Tobias Kuhn from Knowledge Pixels in our paper "Tackling inter-service RDF communication bottlenecks in the Nanopublication Network with Jelly", which was nominated for Best Industry Paper during the SEMANTiCS 2025 Conference in Vienna.
Pure improvements
<4 sec
to transfer 60,000 Nanopublications instead of more than 3 hours before
<1%
of total system time now spent on inter-service communication
Future outlook
Beyond this project, the same communication bottlenecks appear in many client-server and microservice architectures. That’s why we see Jelly as a powerful solution not just for Nanopublications, but for the broader Semantic Web. By improving efficiency and reducing costs, it can help organizations build faster, more competitive products.
Looking ahead, we’re exploring new applications for Jelly, including database replication, RDF change capture, data visualization, and cloud-based triple store access.
For a more in-depth look at the technology behind this success, read our blog post: Streaming Nanopublications with Jelly: The Hidden Costs of Serialization.